






确定有穷自动机分析内核
作者/孙雪青
下载源代码
前些时候学习编译原理,同时也为
DocWizard
做词法分析技术的准备,于是便想出了一种词法分析内核。这个分析内核可以在不改变代码的情况下分析不同的 DFA。
 分析器的基本构造
分析器的基本构造
如图一所示,脚本 Scripts 进入分析内核 ParsingKernel,分析内核根据 DFA 规则作词法分析,生成单词序列
WordsSequence。

图一
其中的 DFA Rules 其实就是 DFA 中的状态转换规则。分析内核在工作时需要查阅规则表。只要更换这个规则表,就可以分析不同的词法。
工作原理
例子程序中的 CStateChangeRule 代表一条转换规则。它由如下三个数据构成:
- 当前状态编号:int nCurState
- 下一个状态编号:int nNextState
- 需要匹配的字符:CHAR_RANGE route[ROUTE_BUF_LEN]
void CAjaxParserDlg::OnParse()
{
char *pszLine = " void CAjaxParserDlg::OnParse() +12.3 12.3 -12.3 -.12 +.12 .12 +12. -12. 12. .023 ";
int i=0, nLen, nState=0, nNext=-1, nStart;
nLen = strlen(pszLine);
while(i<nLen)
{
if(nState==0)
{
nStart = i;
}
nNext = Route(nState, *(pszLine+i));
Accept(nState, nNext, pszLine+nStart, i-nStart);
if(!(nState!=0 && nNext==0))
i++;
nState = nNext;
}
Accept(nState, 0, pszLine+nStart, i-nStart);
}
Route()函数是一个很重要的函数。它负责查阅 DFA 规则表,检索当前状态为 nCurState,并且接受字符 c 的规则。如果检索到了,则返回下一个状态的编号。例子程序中的实现代码效率不高,因为它采用线性搜索。各位可以将其改为更快的搜索算法。
int CAjaxParserDlg::Route(int nCurState, BYTE c)
{
int i, nSize;
nSize = m_ruleArr.GetSize();
CStateChangeRule rule;
for(i=0; i<nSize; i++)
{
rule = m_ruleArr[i];
if(rule.nCurState==nCurState
&& InRoute(c, rule.route))
{
return rule.nNextState;
}
}
if(nCurState==0)
{
Logln("start state, cannot recognize char");
}
// return to state 0 the start state
return 0;
}
Accept()函数比较简单,它负责接受分析得到的单词。如果当前状态是终止状态,并且下一个状态将要转向状态0,则说明现在已经是一个完整的单词了,并且下一个字符将不属于这个单词。这个时候
Accept() 函数调用 Log() 将这个单词输出。在实际应用中,往往需要把单词存放到一个单词数组。
void CAjaxParserDlg::Accept(int nCurrent, int nNext, LPCTSTR pszLine, int nLen)
{
char psz[256];
if(nNext==0 && nCurrent!=0)
{
sprintf(psz, "Accept word(s:%d)[", nCurrent);
Log(psz);
strncpy(psz, pszLine, nLen);
psz[nLen] = 0;
Log(psz);
if(!(m_stateArr[nCurrent].nFlag&STATE_END))
{
Logln("]unrecogized char, can''t accept");
}
else
{
Logln("]");
}
}
}
规则表分析内核赖以工作的“规则”采用 CStateChangeRule 来表示。例子程序中的规则表的初始化在 CAjaxParserDlg::OnInitDialog() 函数中。如下所示是一个规则的建立。
CStateChangeRule rule; rule.nCurState = 0; rule.nNextState = 1; rule.route[0].byStart = ''_''; rule.route[0].byEnd = ''_''; rule.route[1].byStart = ''A''; rule.route[1].byEnd = ''Z''; rule.route[2].byStart = ''a''; rule.route[2].byEnd = ''z''; m_ruleArr.Add(rule); rule.Clear();例子程序中的DFA如图二所示。
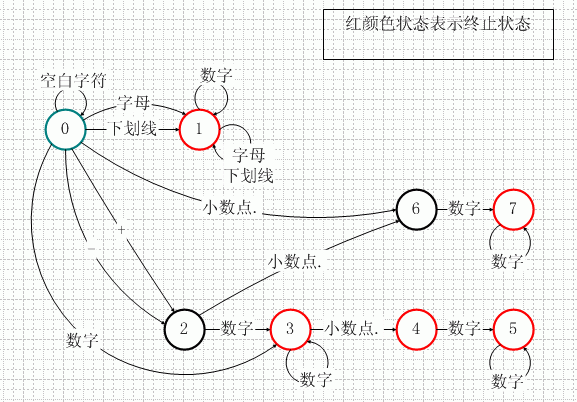
图二
状态属性当然除了规则以外,另一个重要的数据就是状态的属性,分析内核需要知道一个状态是不是终止态。m_stateArr 记录了所有的状态的属性。这个数组的下标代表状态编号,数组元素的值是状态属性。
结束语可能各位都知道,其实作词法分析挺简单的,但是语法分析十分的困难。据我所知,语法分析尚且不十分的形式化,也就是说理论并非十分完善。这将对构造语法分析器带来困难。我做 DocWizard 的时候并没有采用教科书上的语法分析方法,做的很麻烦,而且也不能保证正确。说实在的做得挺滥的。呵呵~~ 希望以后能做得好一些。
下一步我得好好的学习 lex 和 yacc 了。毕竟用它们来构造分析器还是挺轻松的。
作者信息网名: alphasun, shaking
email: alphasun@{域名已经过期}, sun@{域名已经过期}
个人主页: ShakingToolkit
 账号登录
账号登录